图论
邻接表
建无向图的时候,add(a,b), add(b,a)
,所以每条边都是成对的,即编号 \((0,1)、(2,3)、(4,5) \dots\) 是一组
(正向边,反向边), 所以如果 \(i\)
是正向边,那么它的反向边就是 \(i \oplus
1\)
1 | int h[N], e[M], w[M], ne[M], idx; |
最短路
传递闭包
若 \(a \rightarrow b \rightarrow c\)
则连接一条 \(a \rightarrow c\)
的边,即:将所有间接可以到达的点,都用一条直接的边相连起来
1
2
3
4
5
6
7void floyd()
{
for(int k = 0; k < n; k ++)
for(int i = 0; i < n; i++)
for(int j = 0; j < n; j++)
d[i][j] |= d[i][k] && d[k][j];
}
1 | int a, b; |
最小生成树
1 | long long kruskal() |
负环
1 | bool spfa() |
差分约束
最短路的松弛操作: 1
2if(dist[j] > dist[t] + w[i])
dist[j] = dist[t] + w[i];
对于一组不等式: \(x_i \le x_j + c_k\) 其中 \(c\) 是常数,若我们对每一个不等式都从点 \(x_j\) 向点 \(x_i\) 连一条长度为 \(c\) 的有向边(注意方向是从 \(j\) 到 \(i\) ,说明从 \(j\) 可以走到 \(i\) ,即 \(dist[i]\) 可以有可能被 \(dist[j]\) 更新),则跑完最短路之后的 \(dist\) 数组就是原不等式组的一个可行解,无解的情况即有负环存在
证明负环无解
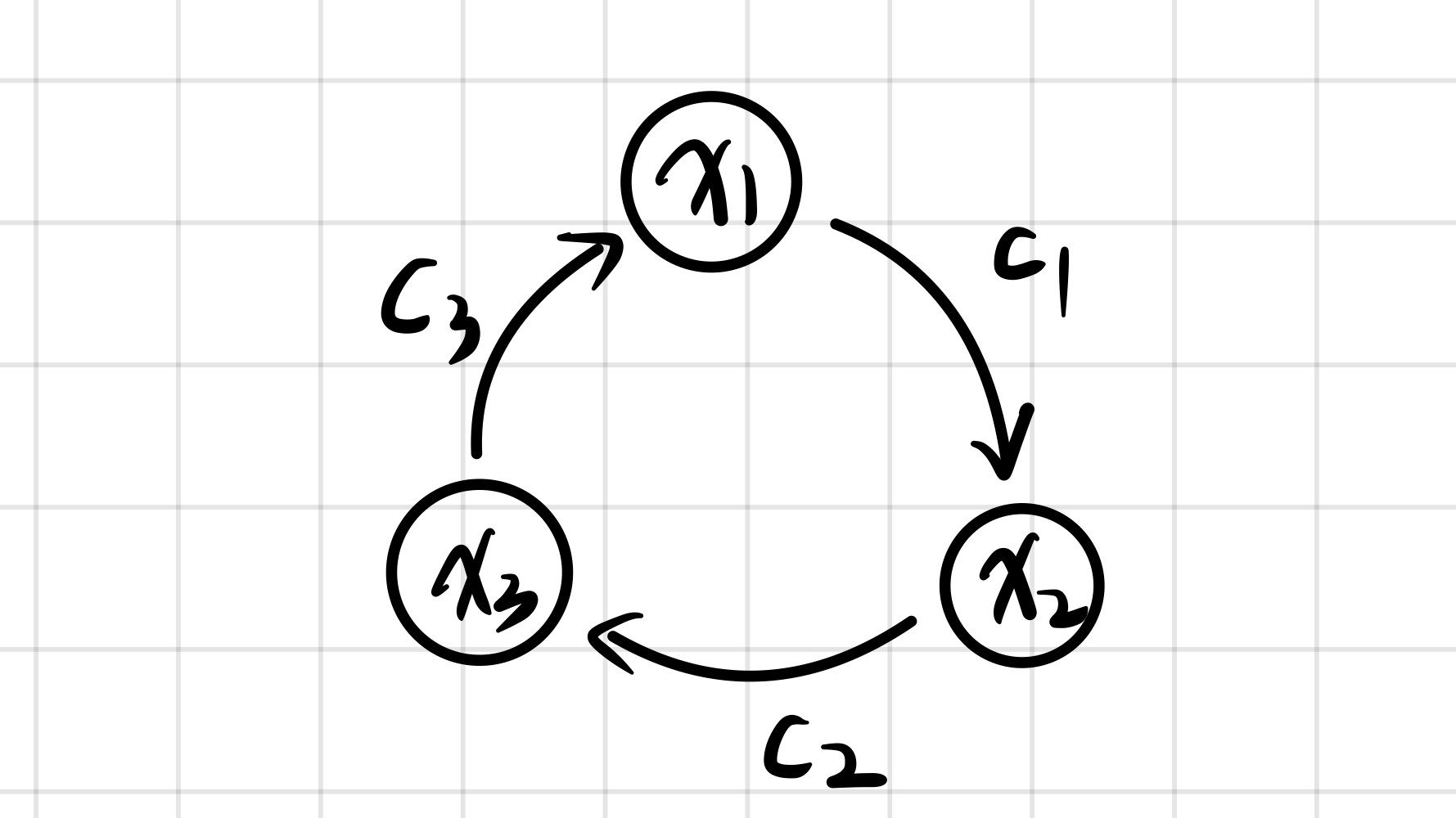
如上图我们建立的不等式关系为: \[ \begin{align} x_2 &\le x_1 + c_1 \nonumber \\ x_3 &\le x_2 + c_2 \nonumber \\ x_1 &\le x_3 + c_3 \nonumber \\ \end{align} \] 我们可以进行一个放缩: \[ \begin{align} x_1 &\le x_3 + c_3 \nonumber \\ &\le x_2 + c_2 + c_3 \nonumber \\ &\le x_1 + c_1 + c_2 + c_3 \nonumber \end{align} \] 由于是负环,所以 \(c_1 + c_2 + c_3 < 0\),则上述不等式说明 \(x_1\) 小于自己加上一个负数,这是显然矛盾的
求最值
若我们要求解这组不等式的每一个变量 \(x\) 的最值,则必有一个约束条件形如:\(x \ge 0\),否则所有等式都是相对关系,我们可以在等式两边同时加上一个常数 \(d\) 来获得新的解,此时变量 \(x\) 的值域可从负无穷到正无穷,无法求出最值
处理形如 \(x_i \le c\) 其中 \(c\) 是一个常数:建立一个源点,假设这个点为 \(0\) 号点,则从 \(x_0\) 向 \(x_i\) 连一条长度为 \(c\) 的有向边,其中 \(x_0 = 0\) 即 \(dist[0] = 0\)
最大值
由于存在最值,我们一定可以将 \(x_i \le x_j + c_i\) 通过如 \(x_i \le x_k + c_j + c_i\) 这样的放缩,放缩到 \(x_i \le x_0 + c_0 \dots + c_i\),由于 \(x_0 = 0\),所以此放缩后的不等式等价于从 \(0\) 号点走到 \(i\) 的所有路径,而我们要求的最大值(\(x_i\) 的上界)就是所有路径长度中的最小值,也即从 \(0\) 号点到 \(i\) 的最短路
最小值
与最大值类似,\(x_j \ge x_i + c_i\),我们最后可以放缩得到 \(x_j \ge x_0 + c_0 \dots +c_i\),此不等式等价于所有从 \(0\) 号点走到 \(j\) 号点的路径长度,而我们要求的最小值(\(x_j\)的下界),就是所有路径长度中的最大值,也即从 \(0\) 号点到 \(j\) 的最长路
做法总结
以最长路为例: 1. 边权无限制:\(\text{spfa} \ \ \ O(nm)\) 2. 边权非负:\(\text{tarjan} \ \ \ O(n + m)\) 3. 边权 \(> 0\) : 拓扑排序 \(O(n + m)\)
连通分量
一些定义
对于一个有向图,连通分量指:对于分量中的任意两点 \(u, v\),必然可以从 \(u\) 走到 \(v\), 且从 \(v\) 走到 \(u\)
强连通分量(SCC):极大连通分量
桥:对于一个连通图来说,如果把某条边删掉之后,会使得原来的整个连通图变得不连通,这个边就称作桥
等价地说,一条边是一座桥当且仅当这条边不在任何环上边双连通分量(e - DCC):极大的,不含有桥的连通分量
性质:任意两点之间含有两条不相交的路径割点:对于一个连通图,如果把某个点删掉()会删除与其关联的所有边)之后,整个图会变得不连通,那么这个点就称为割点
每个割点:至少属于两个连通分量点双连通分量(v - DCC):极大的,不含有割点的连通分量
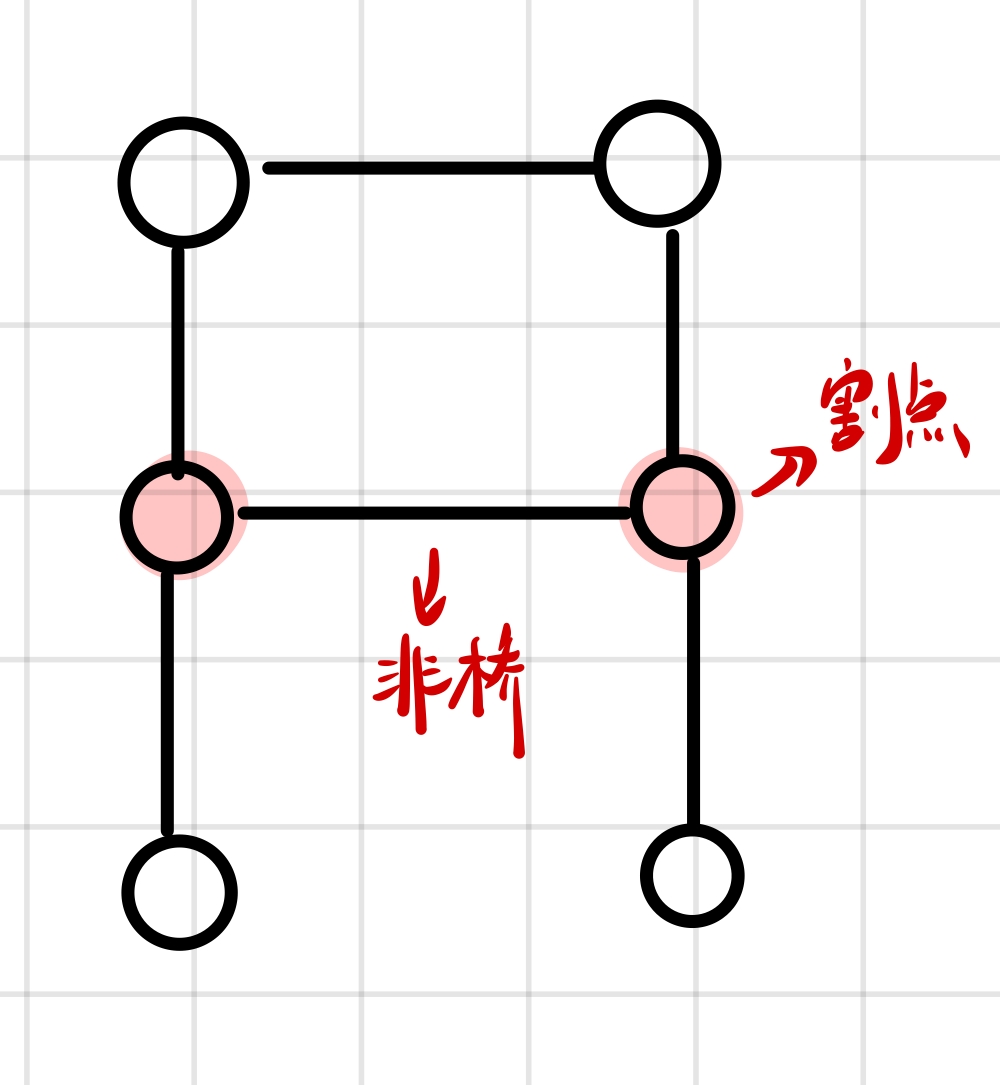
两个割点之间的边不一定是桥:
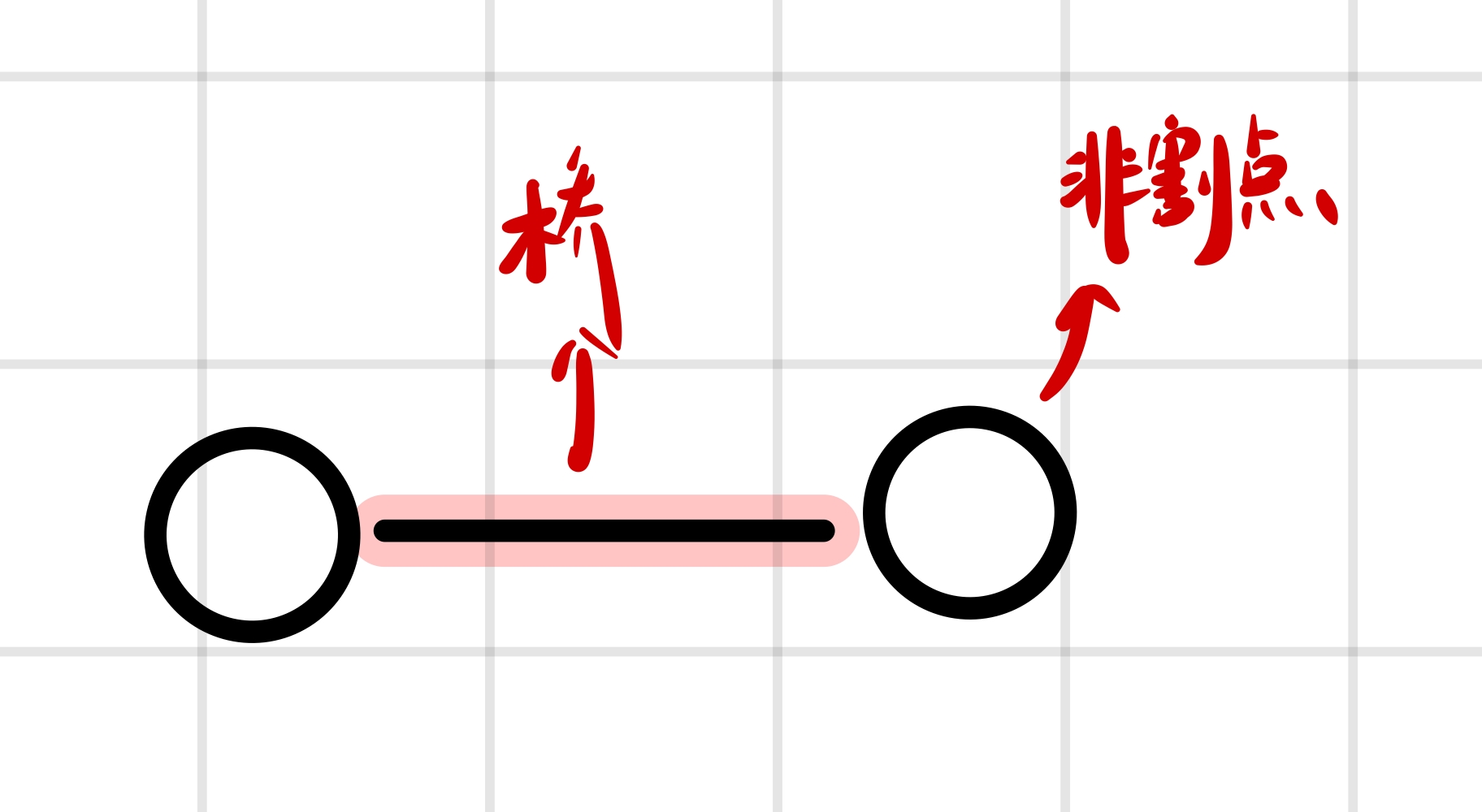
一个桥的两个端点不一定是割点(一个点连通分量不一定是边连通分量):
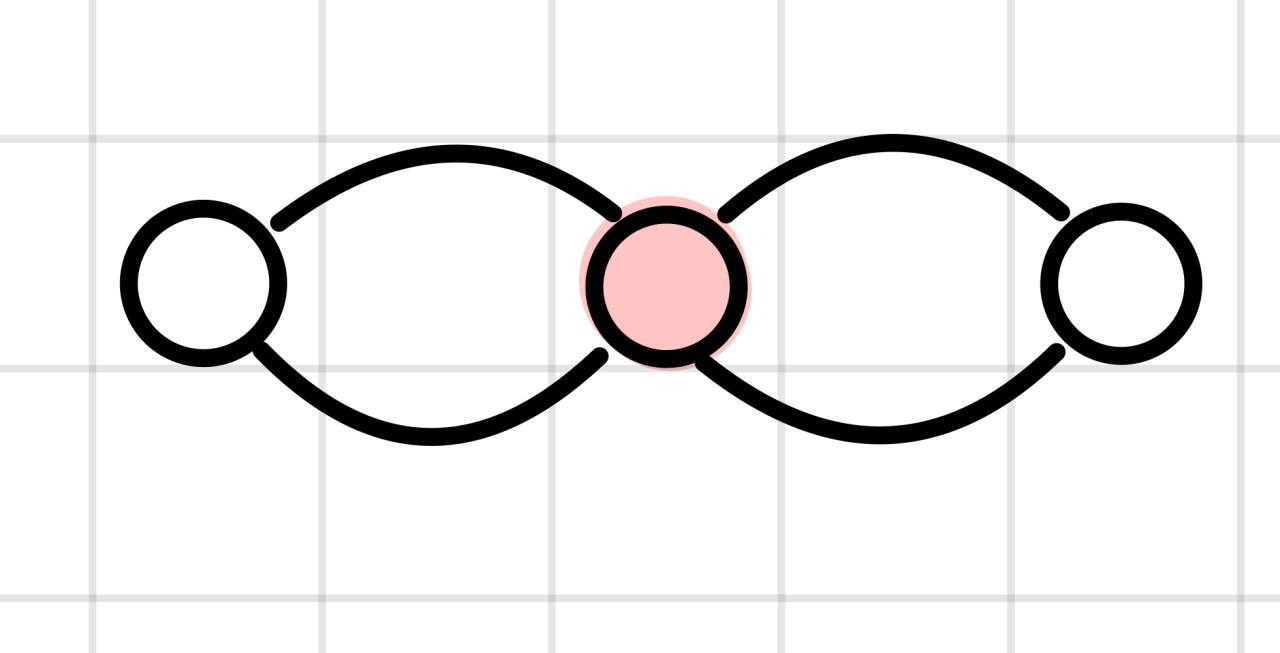
一个边连通分量不一定是点连通分量:
一些结论
- 将有向图变成强连通分量所需要加的最少边数为 \(\max(p, q)\),其中 \(p\) 是缩点之后入读为 \(0\) 的点的数量, \(q\) 是缩点之后出度为 \(0\) 的点的数量
- 将无向图连通图变成边双连通分量所需要加的最少边数是 \(\lceil cnt / 2 \rceil\),其中 \(cnt\) 是缩点之后叶子节点的数量
有向图的强连通分量
有可能可以将强连通分量缩点之后,变成一个拓扑图进行递推
\(\text{Tarjan}\) 求 \(\text{SCC}\) :
在 DFS 的过程中:树枝边,前向边,后向边,横叉边
如果 \(x\) 在强连通分量中:1. 存在后向边指向祖先节点 2. 先走到横叉边,横叉边再走到祖先节点
对每个点定义两个时间戳:\(\text{dfn}[u]\) 表示遍历到 \(u\) 的时间戳,\(\text{low}[u]\) 表示从 \(u\) 开始走,所能遍历到的最小时间戳
\(u\) 是其所在强连通分量的最高点 \(\iff \text{dfn}[u] == \text{low}[u]\)
代码中的
else if (in_stk[j]) low[u] = min(low[u], dfn[j]); 可以改为
else if (in_stk[j]) low[u] = min(low[u], low[j]);
原因(?
else if 那一行里面能不能把 dfn[j] 换成 low[j] 呢?显然是可以的,
这一行只会在压缩点的过程中用到,因为非压缩点是按照拓扑序遍历的,拓扑序不会遍历到之前搜到的点,否则就成环了。 在压缩的过程中我们也只会在拆环的时候(即遍历到一个环的起点的时候)才会用到这一行,如果是原代码那么返回路径上存的就是起点的实际编号值dfn,
如果改成 low 呢?只有从起点已经遍历过一个环了,并且终点在起点前面,那么 low 就是存的前面起点的值,即我们刚遍历大环成为一个相对的小环了,这时候存的此时起点能走到的最小值
会不会改了之后成为一个较大值呢?不会,因为low是通过两次min函数比较出来的,最起码比自己的编号值要小,不然也不会完成赋值。
我们可以讨论一下两种写法的意义何在呢?
第一种模板的写法将拆环的起点编号dfn存到每一个点的 low 里面去了,因为 dfn 编号是不参与比较与赋值的锚定顺寻的编号,所以我们可以知道每一点第一次拆环的时候是从哪个起点上面拆下来的
改成 low 之后我们就只能知道每一个点第一次拆环的时候在环上面能追溯到最前面的环起点是哪一个值
作者:BT7274 链接:https://www.acwing.com/file_system/file/content/whole/index/content/5627037/ 来源:AcWing 著作权归作者所有
缩点:从每个点出发遍历邻边,如果这条边的两个点属于不同的强连通分量,就加一条边
1 | void tarjan(int u) |
无向图的边双连通分量
如何找到所有桥:设当前在搜的节点是 \(x\),向下再搜一条边到节点 \(y\),若 \(y\) 可以走到 \(x\) 或者 \(x\) 的祖先节点,那么这条 \(x——y\) 的边就不是桥,否则 \(y\) 最早只能走到 \(y\) 自己,那么这条边就是桥,因此,是桥 \(\iff \text{dfn}[x] < \text{low}[y]\)
如何找到所有的边双连通分量:若 \(\text{dfn}[x] == \text{low}[x]\),则说明,\(x\) 向上的那条边是桥,则当前在栈中的,\(x\) 的子树节点,就是一个边双连通分量
为什么这里不用记录是否在栈中:可能是因为无向图在搜的时候没有横向边,\(u\) 不会搜到已经在其他边双连通分量的点了,所以只要是 \(u\) 可以走到的点,就能用来更新 \(\text{low}[u]\)
同一个边双连通分量中的点的 low 标记不一定都相同
1 | void tarjan(int u, int from) |
无向图的点双连通分量
如何求割点:从点 \(x\) 向下再搜一条边到点 \(y\),若 \(y\) 不可以走到 \(x\) 的祖先节点: 1. \(x\) 不是根节点,那么 \(x\) 是割点 2. 如果 \(x\) 是根节点,则如果有至少两个 \(y_i\) 满足 \(\text{low}[y_i] \ge \text{dfn}[x]\),则 \(x\) 是割点
缩点: 1. 每个割点单独作为一个点 2. 从每个 v-DCC
向其所包含的每个割点连一条边 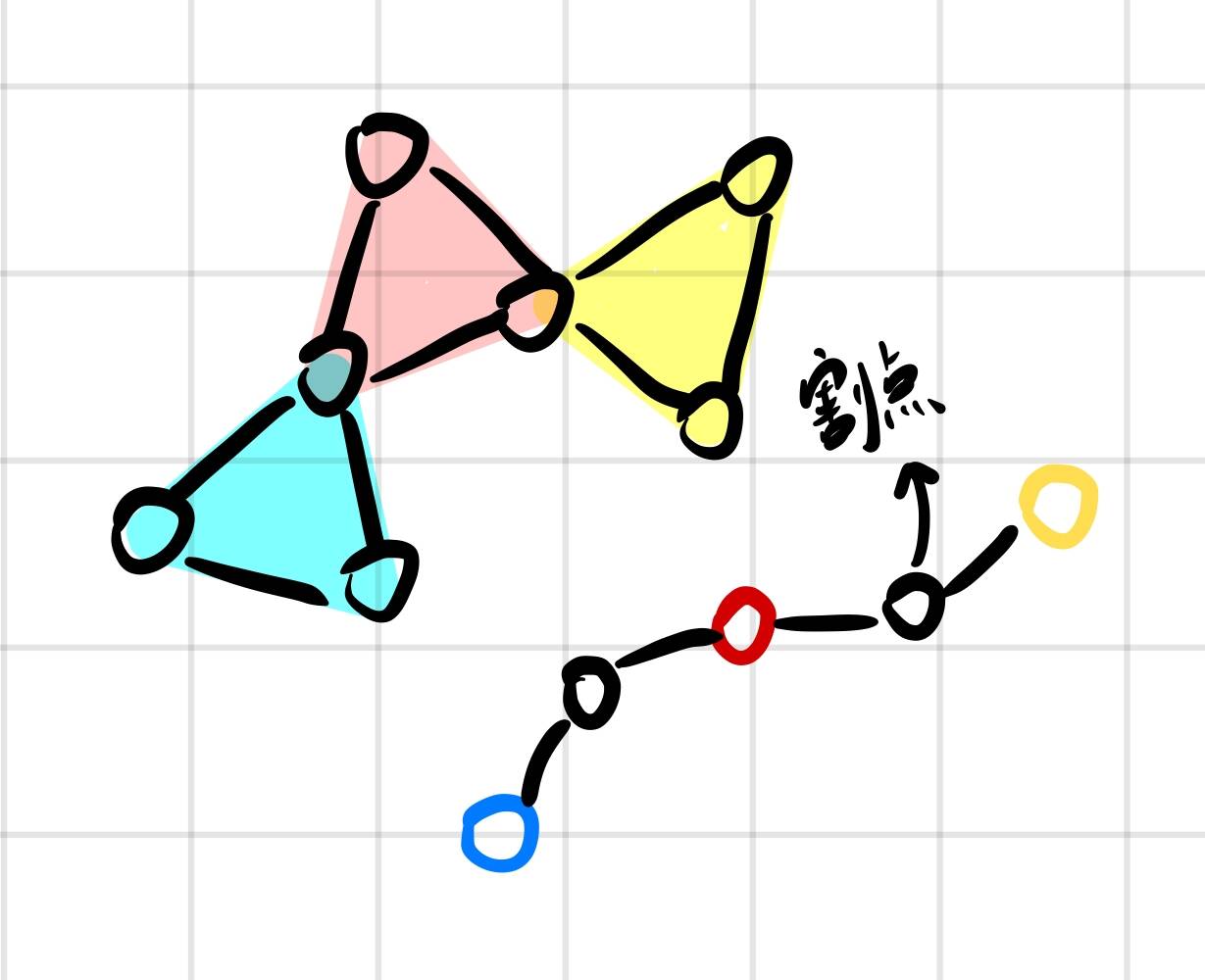
对于缩点之后的节点,每个节点(除了割点之外)的度数就代表它所代表的 v-DCC 中有几个割点
else low[u] = min(low[u], dfn[j]); 中不可以将
dfn[j] 换成 low[j]
原因:会使得无法找到某些割点
>对于求割点来说,我们考虑的是删掉这个点之后的剩余部分还能不能联通,如果此时我们采用这种更新方式,可能就会存在某个点,它更新后反而能回到我们考虑的点的上方(通过间接方式),根据我们对割点的判断low[x]
<= low[y],
我们会发现此时x居然不被判定为割点了。原因就在于,我们在间接去到S的时候,没有考虑到,割点会删掉x,这样子我们根本没法越过x去s
1 | void tarjan(int u) |
1 | for(int root = 1; root <= n; root++) |
1 | //求每个 v-DCC 的割点数量(度数) |
LCA
倍增LCA
\(\text{fa}[i,j]\) 表示从 \(i\) 开始, 向上跳 \(2^j\) 步所到达的点 哨兵:如果从 \(i\) 开始跳 \(2^j\) 步会跳过根节点,那么 \(\text{fa}[i,j] = 0, depth[0] = 0\)
- 先将两个点跳到同一层
- 如果没有跳到同一个点,就让两个点同时往上跳,一直跳到它们的最近公共祖先的下一层
预处理 \(O(n \log n)\)
查询 \(O(\log n )\)
1 | void bfs(int root) // 预处理倍增数组 |
离线LCA, \(O(n + m)\)
以询问树中两个点的最小距离为例: 在深度优先遍历时,将所有点分成三大类: 1. 已经遍历过,且回溯过的点,状态标记为 \(2\) 2. 正在搜索的分支,状态标记为 \(1\) 3. 还未搜索到的点,状态标记为 \(0\)
对于当前正在搜索的点 \(x\),去找一下所有与这个点相关的询问,如问 \(x\) 和点 \(y\) 的最近公共祖先是谁,如果点 \(y\) 的状态是 \(2\),那么它们的最近公共祖先就是 \(\text{find}[y]\)
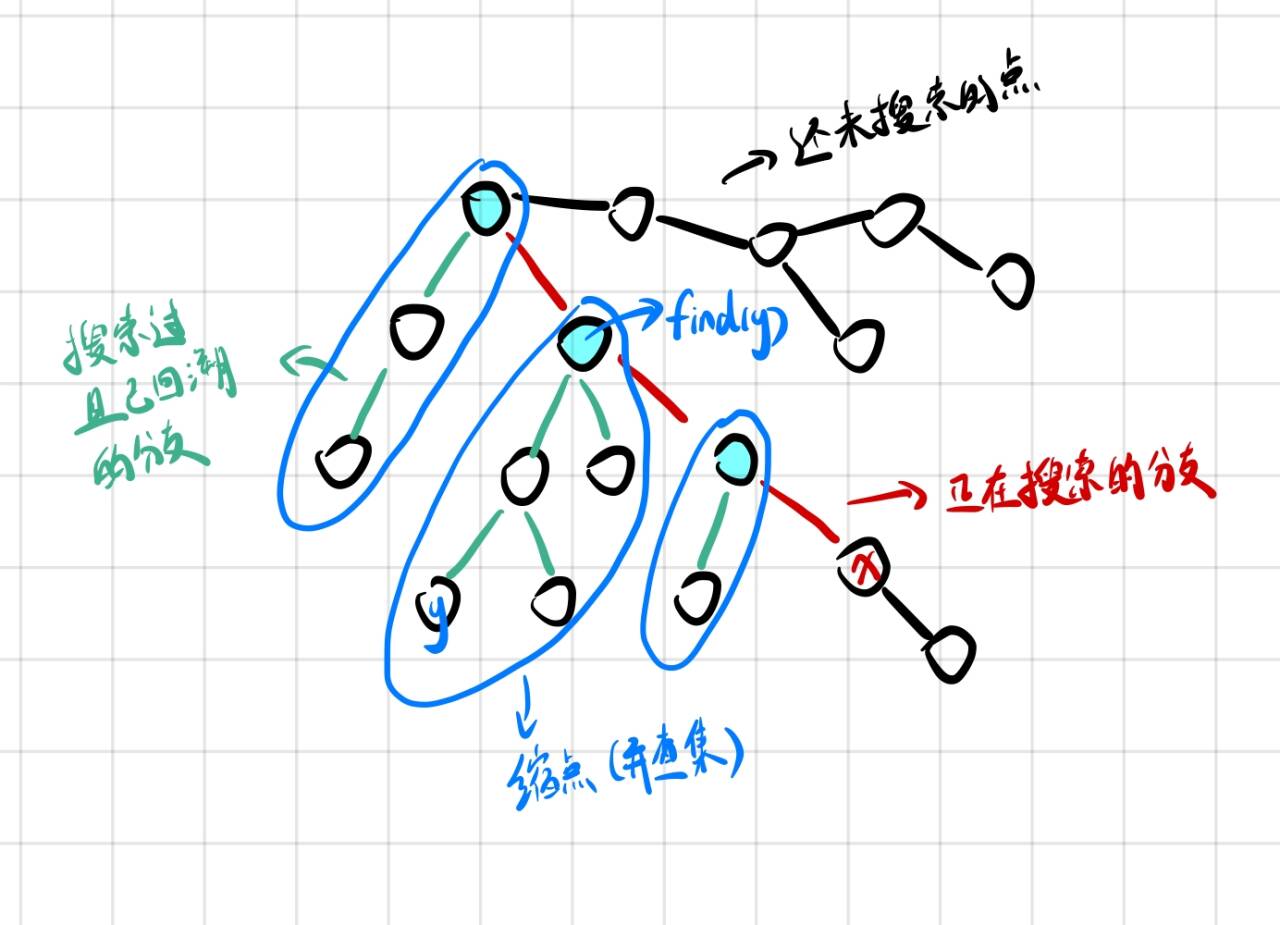
1 | int p[N]; |
二分图
前置术语
最大匹配:选出最多的边数,使得任意两条边都没有公共点
增广路径:从一个非匹配点出发,沿着非匹配边——匹配边——非匹配边——匹配边 \(\dots\) 交替走,若最后能走到另一个非匹配点,则称这条路径为增广路径
最大匹配 \(\iff\) 不存在增广路径,因为如果存在增广路径,我们可以将路径上的所有匹配边变成非匹配边,非匹配边变成匹配边,此时匹配数量就增加 \(1\) 了
最小点覆盖:选出最少的点数使得可以覆盖所有边
最大独立集:选出最多的点,使得选出的内部点之间没有边
最大团(最大独立集的补图):选出最多的点,使得选出的内部点,任意两点之间都有边
最小路径点覆盖:对于一个DAG(有向无环图),用最少的互不相交的路径将所有点覆盖
最小路径重复点覆盖:与最小路径点覆盖不同的是:路径可以相交
二分图
- 二分图:可以将一个图的点分成两个集合,使得图中的所有边都在这两个集合之间,集合内部没有边
- 一个图是二分图 \(\iff\) 不存在奇数环 \(\iff\) 染色法不存在矛盾
- 对于 \(N \times M\) 的网格,我们将所有横纵坐标之和为偶数的染成黑色,横纵坐标之和为奇数的染成白色,在某些情况下可以看做是二分图
- 在二分图中,最小点覆盖 \(=\)
最大匹配数
证明
首先显而易见,最小点覆盖一定 \(\ge\) 最大匹配数,以下证明等于号成立:
- 求最大匹配
- 从左部每一个非匹配点出发做一遍增广路径标记所有经过的点
- 构造:选择左部所有未被标记的点和右部所有被标记的点
证明:由于不存在增广路径,所以从左边的非匹配点出发一定不会走到右边的非匹配点,所以右边的所有非匹配点均未被标记
由于从左边的非匹配点出发,所以左边的所有非匹配点均被标记
在一条匹配边两端的点,要么同时被标记,要么同时不被标记,因为左边的匹配点只会从右边的匹配点走过来,所以左边的匹配点的标记状态和这条匹配边连接的右边的点的标记状态相同
对于所有匹配边: 如果对应的匹配点被标记了我们选择右边的点,否则选择左边的点(保证了所有匹配边被选到了
对于所有非匹配边(可以保证所有非匹配边都被选到:
- 左边的匹配点——右边的匹配点:若左边的匹配点被标记了,那么经过这条非匹配边,右边的匹配点也一定会被标记,由于右边的匹配点一定存在一条匹配边,且被标记了,所以我们会选择右边的点,若左边的匹配点没有被标记,同理我们会选到左边的点,即这条非匹配边一定会被选到
- 左边的匹配点——右边的非匹配点:我们可以知道右边的那个非匹配点一定没有被标记,若左边的匹配点被标记了,那么就一定可以从左边的这个匹配点走到右边的非匹配点,右边的点就会被标记,产生矛盾,所以左边的的匹配点也一定不会标记,对于左边的匹配点,一定会存在一条匹配边,由于没有被标记,我们选择了左边的点,所以所有从左边匹配点连接向右边非匹配点的边都会被选择到
- 左边的非匹配点——右边的匹配点:我们可以知道左边的那个非匹配点一定被标记,并且会从这个非匹配点出发经过右边的匹配点,所以右边的那个匹配点也一定被标记了,而右边的匹配点一定属于某一条匹配边,由于被标记了,那么右边的这个点就一定会被选择上,所以所有从左边非匹配点连向右边匹配点的边都会被选上
- 左边的非匹配点——右边的非匹配点:我们就可以添加一条新的匹配边了,与最大匹配矛盾,所以不存在这样的边
- 在二分图中,求最大独立集 \(\iff\) 去掉最少的点,将所有边都破坏掉 \(\iff\) 找最小点覆盖 \(\iff\) 找最大匹配,因此若总点数是 \(n\) ,最大匹配数是 \(m\) ,则最大独立集是 \(n - m\)
- 最小路径点覆盖:将所有点拆为两个点,分别为 \(i\) 和 \(i'\),对于一条有向边 \((i,j)\) ,就连一条边从 \(i\) 到 \(j'\), 那么原图就可以变为二分图,在新图上求最大匹配就是最小路径点覆盖,但是在写代码的时候不用真的拆点(),\(d[i][j]\) 就可以表示是从 \(i\) 向 \(j'\) 的边
- 最小路径重复点覆盖:先对原图求一遍传递闭包,然后再在新图上求最小路径点覆盖,就是原图的最小路径重复点覆盖
匈牙利算法
1 | bool find(int x) |
欧拉路径/回路
- 无向图,所有边都是连通的
- 存在欧拉路径的充分必要条件:度数为奇数的点只能有 \(0\) 个或者 \(2\) 个
- 存在欧拉回路的充分必要条件:度数为奇数的点只能有 \(0\) 个
- 有向图,所有边都是连通的
- 存在欧拉路径的充分必要条件:所有点的出度均等于入度;或者除了两个点之外,其余所有点的出度等于入度,且剩余的两个点满足:一个点出度比入度多 \(1\) (起点),另一个点满足入度比出度多 \(1\) (终点)
- 存在欧拉回路的充分必要条件:所有点的出度均等于入度
1 | int cnt = 0; |